The power of Query
Quite often performance is the key element that makes customers either very happy with a solution or very unhappy. We, at Xpand, have seen millions of lines of code and I must admit that NAV developers too seldom think about the speed of execution of what they write. Even though it is a rather compelling topic, we are not going to discuss it within this article. Instead, let us concentrate on how to rewrite your code using queries and increase the speed of a solution a thousand fold!
Understanding of basics
Before we dig into examples and queries, it is
important to understand what happens on the SQL server when we write such basic
commands as FINDSET. Let’s check it!

Imagine that we have the following simple
code:
CustLedgerEntry.RESET;
CustLedgerEntry.FINDSET;
When you execute it, NAV will translate this
code into a T-SQL statement similar to the one below:
SELECT "timestamp","Entry No_","Customer No_","Posting Date","Document Type","Document No_","Description","Currency Code","Sales (LCY)","Profit (LCY)","Inv_ Discount (LCY)","Sell-to Customer No_","Customer Posting Group","Global Dimension 1 Code","Global Dimension 2 Code","Salesperson Code","User ID","Source Code","On Hold","Applies-to Doc_ Type","Applies-to Doc_ No_","Open","Due Date","Pmt_ Discount Date","Original Pmt_ Disc_ Possible","Pmt_ Disc_ Given (LCY)","Positive","Closed by Entry No_","Closed at Date","Closed by Amount","Applies-to ID","Journal Batch Name","Reason Code","Bal_ Account Type","Bal_ Account No_","Transaction No_","Closed by Amount (LCY)","Document Date","External Document No_","Calculate Interest","Closing Interest Calculated","No_ Series","Closed by Currency Code","Closed by Currency Amount","Adjusted Currency Factor","Original Currency Factor","Remaining Pmt_ Disc_ Possible","Pmt_ Disc_ Tolerance Date","Max_ Payment Tolerance","Last Issued Reminder Level","Accepted Payment Tolerance","Accepted Pmt_ Disc_ Tolerance","Pmt_ Tolerance (LCY)","Amount to Apply","IC Partner Code","Applying Entry","Reversed","Reversed by Entry No_","Reversed Entry No_","Prepayment","Payment Method Code","Applies-to Ext_ Doc_ No_","Recipient Bank Account","Message to Recipient","Exported to Payment File","Dimension Set ID","Direct Debit Mandate ID"
FROM "Xpand".dbo."CRONUS International Ltd_$Cust_ Ledger Entry" WITH(READUNCOMMITTED)
ORDER BY "Entry No_" ASC OPTION(OPTIMIZE FOR UNKNOWN, FAST 50)
Problem 1. Too many fields
As you can see, NAV will get all the fields from the CustLedgerEntry table into the SELECT statement. This is very handy because later, when you want to read value from any field from the CustLedgerEntry record, NAV will already have it and no additional statement will have to be sent. So, when you do something like this:
CustLedgerEntry.RESET;
IF CustLedgerEntry.FINDSET THEN
REPEAT
IF CustLedgerEntry.Amount > 0 THEN BEGIN
// any action
// any action
END;
UNTIL CustLedgerEntry.NEXT = 0;
and you check the value in the Amount field,
the system will already have the value from the Amount field. Basically,
because NAV does not know in advance which values you may need after the
FINDSET statement is executed, it gets values for all the fields inside the
SELECT statement. Actually, every time you write the FINDSET statement, the
system sends the SELECT * command to the SQL server, even though you may
actually need only one column from your record.
Normally, this is considered to be bad practice for a couple of reasons:
1) With SELECT *, we simply get too much data. This causes more data than needed to move from the SQL server to the client, slowing down performance by at least increasing your traffic. It seems to be rather simple, but on big tables the difference can be impressive.
2) With SELECT *, the system always has to come back to the clustered index to get values for fields that were not indexed and do not exist in the secondary key. There is a term called covering index. Here is the description from Microsoft: “A covering index is the index that contains all output fields required by the operation performed on that index. A covering index data access strategy can greatly improve performance because the database must retrieve only data from the index instead of finding data by using the index and then retrieving the data in the clustered index”. Let’s check an example.
CustLedgerEntry.RESET;
CustLedgerEntry.SETRANGE("External Document No.",ExternalDocumentNo);
CustLedgerEntry.FINDSET;
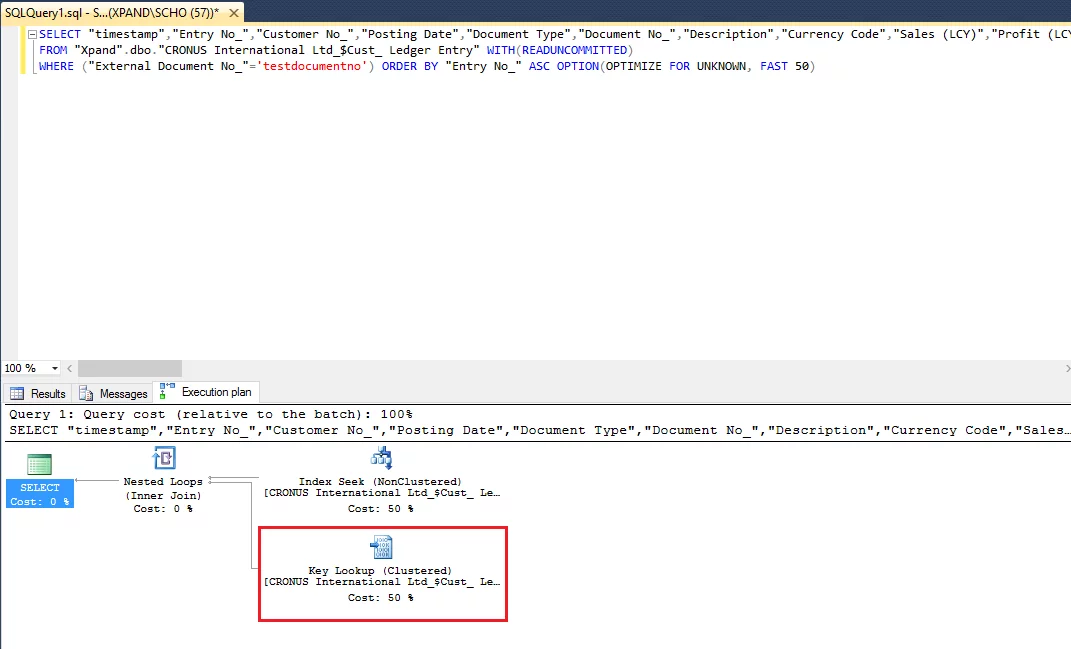
As you can see from the execution plan, the system
selected the non-clustered index (which is the one you see on the screenshot
below), performed Seek of records there, but could not find values for all the
fields in the index and therefore made a lookup to the primary key (clustered
index).
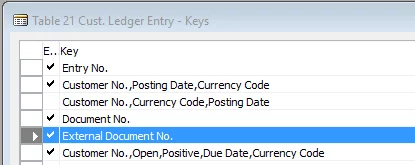
Both operations, Index Seek and Key Lookup,
took approximately 50%, which means that if the index that we used had had all
the fields we needed, our query would have been twice as fast! Or, from another
perspective, if we needed (and specified it in our SELECT statement) only
fields that are available within our non-clustered index, we would have a huge
increase in performance:
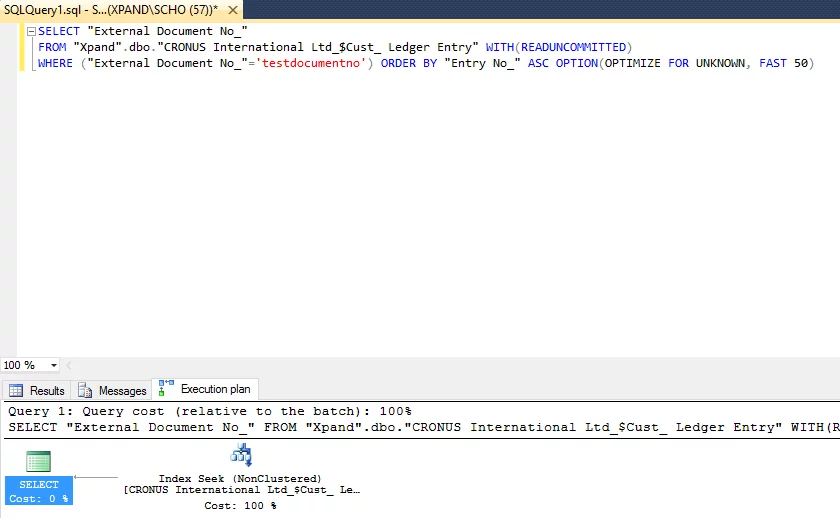
If anyone from Microsoft reads this article, please, think of either allowing us to define needed fields per specific Record variable or change the compiler in such a way that it automatically checks all the usages of a variable and makes the correct SELECT statement with only used fields inside. J
Problem 2. Loop inside loop
Very often developers write the REPEAT...UNTIL statement inside another REPEAT…UNTIL. For example, you may want to go through specific customers and then loop through their sales invoices. The task does not sound very weird or difficult to execute. Most of developers would write something like this:
Customer.RESET;
Customer.SETRANGE("Currency Code",'');
IF Customer.FINDSET THEN
REPEAT
SalesHeader.RESET;
SalesHeader.SETRANGE("Sell-To Customer No.",Customer."No.");
IF SalesHeader.FINDSET THEN
REPEAT
// any action
UNTIL SalesHeader.NEXT = 0;
UNTIL Customer.NEXT = 0;
I bet you have seen this structure a bunch of times. Some of you may have even seen another level of loop - under the SalesHeader record. And unfortunately, this is bad, since it is extremely performance-killing. With this structure, we are making a system loop through every single record (which fits the filter, of course) in the Customer table, and then, in the Sales Header table, per Customer record. This is time-consuming (especially for big tables) and always makes your solutions look like this guy:

Solution
There is a very fairly simple solution to bothproblems -> an object of type Query! Let’s first discover how it can help
with the first problem. The thing is that when you execute a query with a
defined list of fields, the system sends the SELECT statement ONLY for fields
that were defined in the query. Not all fields, but only those you really need.
For example, let’s create the following query:
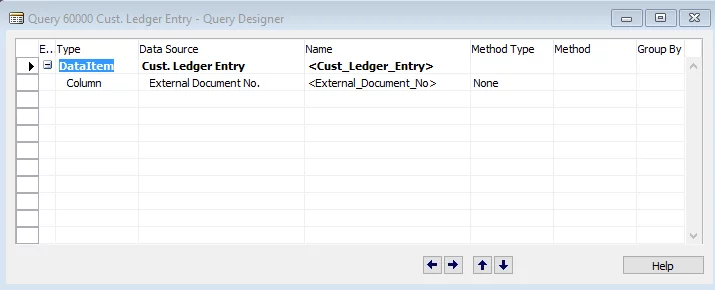
After you execute it with code as follows:
CLEAR(CustLedgerEntryQuery);
CustLedgerEntryQuery.OPEN;
WHILE CustLedgerEntryQuery.READ DO
BEGIN
// any action
END;
CustLedgerEntryQuery.CLOSE;
the system will generate a T-SQL statement
similar to the one below:
SELECT "Cust_Ledger_Entry"."External Document No_" AS "External_Document_No","Cust_Ledger_Entry"."Entry No_" AS "Cust_Ledger_Entry$Entry No_"
FROM "Xpand".dbo."CRONUS International Ltd_$Cust_ Ledger Entry" AS "Cust_Ledger_Entry" WITH(READUNCOMMITTED)
ORDER BY "Cust_Ledger_Entry$Entry No_" ASC OPTION(OPTIMIZE FOR UNKNOWN, FAST 50, FORCE ORDER, LOOP JOIN)
As you can see, only the External Document No. field is selected by the system. This is pretty cool, because we a) only ask SQL what we really need and b) in many cases we could eliminate the Key Lookup to the clustered index because we could take advantage of the covering index having all the fields in the non-clustered index. No excessive data, no excessive load on the network and RAM, and no extra lookup for fields, which we simply do not need and could take directly from the non-clustered index. Pure performance increase.
Now, in order to solve the “loop inside loop” issue you could create a very simple query that would perform a simple JOIN of two tables. Let’s use our example above and create the following query:
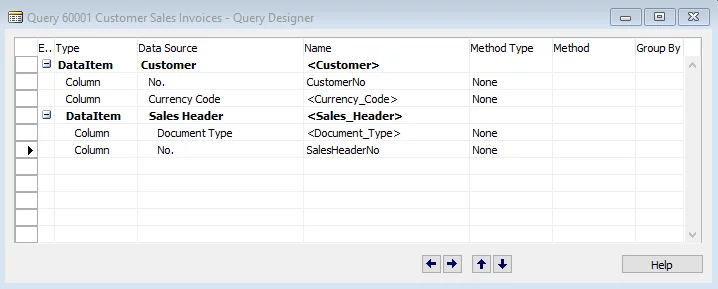
And execute it. We will get one SQL query:

By doing so, we will get a single query with
only those fields that we need and, which is more important, we will have to
loop only once and only on the result set:
CLEAR(CustomerSalesInvoices);
CustomerSalesInvoices.SETRANGE(Currency_Code,'');
CustomerSalesInvoices.OPEN;
WHILE CustomerSalesInvoices.READ DO
BEGIN
// any action
END;
CustomerSalesInvoices.CLOSE;
The increase of speed in this case is impressive in almost every case. And by impressive we mean 10 or even 100 times faster.
In this article, we have explored only two small problems, which could be finetuned already today with really powerful results. We believe that the introduction of queries in NAV 2013 has been underestimated by partners and we really recommend using it. Just like we do in our daily development. J